Что такое LLM

LLM (Large Language Model) — это большая языковая модель, нейросеть с миллиардами параметров. Она обучена на колоссальных массивах текстовых данных (научных публикациях, художественной литературе, справочных материалах), умеет распознавать и имитировать естественную речь.
Оглавление
LLM — что это?
LLM — это программа, которая настолько хорошо изучила статистику языка, что создает иллюзию осмысленного диалога. Этот тип нейросетей обучен определять последующий токен (кусочек текста, который обрабатывается за один шаг, например, слово, слог, символ) на основе полученной информации. Например: получив начало фразы «Столица России — …», языковая модель LLM вычислит, что с высокой вероятностью дальше последует слово «Москва».
Что умеют делать LLM
- Общаться с пользователями.
- Генерировать контент.
- Выполнять машинный перевод.
- Сжимать длинные тексты до коротких пересказов.
- Распознавать эмоции в тексте.
- Вести диалог с пользователем.
- Писать код на различных языках программирования.
Обработка естественного языка (NLP) — это целое научное направление, в котором LLM сегодня занимают центральное место.
Как работает большая языковая модель
Многие современные большие языковые модели базируются на архитектуре трансформера (Transformer). Ее предложил Google еще в 2017 году в статье «Attention is All You Need» (внимание — это все, что вам нужно).
Трансформер обрабатывает весь текст одновременно посредством механизма внимания (self-attention). С его помощью модели могут вычислять степень взаимосвязи внутри предложения или всего текста. Например, в предложении «Анна взяла книгу, так как она была очень интересной» механизм внимания помогает модели понять, что местоимение «она» относится к «книге», а не к «Анне».
Процесс того, как работают LLM, можно разбить на три этапа:
- Предобучение (pre-training). Модель учится определять следующий токен.
- Токенизация — текст делится на токены, каждый из которых переводится в числовой вектор для обработки нейросетью.
- Дообучение (fine-tuning) — модель обучают на парах «вопрос — правильный ответ», а люди проверяют ее ответы (RLHF).
Важно понимать: LLM — это генеративный ИИ, который создает правдоподобные тексты на основе статистических закономерностей и может уверенно врать (галлюцинировать).
А это верный ответ:
Какие бывают виды LLM
Большие языковые модели классифицируют по трем основным признакам: открытости кода, назначению, способности обрабатывать разные типы данных.
- Открытые (open-source) — код и веса модели можно скачать и доработать (семейство Qwen, DeepSeek, Saiga).
- Проприетарные (закрытые) — доступ только через API или интерфейс, код не раскрывается (ChatGPT, Gemini, GigaChat, Claude).
- Общего назначения — решают широкий круг задач (ChatGPT, GigaChat): умеют писать тексты, переводить, программировать.
- Специализированные — заточены под конкретную область (медицина, юриспруденция, генерация кода). Например: Codestral, T-lite, Med-PaLM 2, FoxBrain.
- Мультимодальные — способны работать с разными данными: картинками, видео, аудио (Gemini, Qwen-VL, GigaChat).
- Автоматизируют поддержку.
- Генерируют контент.
- Анализируют отзывы.
- Переводят с иностранных языков.
- Помогают писать код.
- Автоматически создают описания к функциям.
- Ищут уязвимости и неоптимальные решения.
- искать информацию;
- резюмировать документы;
- писать и переводить тексты;
- создавать изображения;
- придумывать идеи, например, для подарков, путешествий, новых рецептов;
- объяснять сложное простыми словами.
Где применяются большие языковые модели
Бизнес и маркетинг
В PromoPult инструменты на основе LLM помогают быстро и правильно настроить кампании в прямых аккаунтах Яндекс Директа и VK Рекламы. Вам нужно лишь ответить на вопросы чат-бота, а нейросеть составит заголовки и тексты объявлений, сгенерирует креативы, настроит таргетинги. Создавайте прямые аккаунты в Директе и VK Ads через PromoPult, запускайте продвижение и возвращайте до 19% от затрат на внешнюю рекламу бонусами.
Реклама. ООО «Клик.ру», ИНН:7743771327, ERID: 2VtzquWWxi4
Программирование и IT
Наука и образование
LLM помогают ученым в самых разных областях — от анализа текстов до расшифровки древних символов и планирования космических миссий.
В образовании LLM становятся личными помощниками для учеников, студентов и даже учителей. По сути, у студентов и школьников появляется репетитор, который доступен 24/7 и умеет объяснять любые сложные темы.
Повседневное использование
LLM модель помогает:
В 2026 году большие языковые модели стали таким же универсальным инструментом, как интернет или смартфон. Их применяют везде, где есть текст: от бизнеса до повседневного общения.
Плюсы и минусы LLM
| Преимущества | Недостатки |
|---|---|
| Универсальность — одна модель решает сотни задач: перевод, генерацию, анализ, диалог | Галлюцинации — уверенные, но неверные ответы. Невнимательность пользователя или неправильный промпт могут стать причиной критической ошибки |
| Скорость и масштабируемость — обрабатывают тексты за секунды, работают 24/7 без перерывов | Отсутствие понимания — модель не осознает смысл, она лишь имитирует речь на основе собранных данных |
| Доступность знаний — аккумулируют информацию из миллионов источников | Высокая стоимость — обучение одной модели стоит десятки миллионов долларов |
| Снижение порога входа — писать код или текст может человек без профильного образования | Предвзятость — LLM наследуют предрассудки из обучающих данных |
| Автоматизация рутины — освобождают время для творческих задач | Риск нарушения конфиденциальности, так как использование облачных моделей требует передачи данных сторонней компании |
| Круглосуточная доступность — не болеют, не устают, не уходят в отпуск | Огромное энергопотребление — обучение и работа LLM требуют колоссальных вычислительных ресурсов |
Сравнение популярных LLM
Чтобы помочь сориентироваться в многообразии языковых моделей и выбрать подходящий инструмент под свои задачи, подготовили сравнение пяти популярных LLM:
| Параметр | GPT-4 | Gemini | Claude | YandexGPT | GigaChat |
|---|---|---|---|---|---|
| Разработчик | OpenAI | Google DeepMind | Anthropic | Яндекс | Сбер |
| Актуальная версия (на момент данных) | GPT-4o (13 мая 2024) | Gemini 3 (дек. 2025) | Claude Sonnet 4.6 (фев. 2026) | YandexGPT 5.1 (авг. 2025) | GigaChat 3 |
| Мультимодальность | Да (текст + изображения) | Да (текст + изображения) | Да (текст + изображения с Claude 3) | Нет (только текст) | Да (текст + изображения через Kandinsky 5.0; аудио через GigaAM v3) |
| Контекстное окно (макс.) | До 32 768 токенов (~25 тыс. слов) | 1 млн токенов (Gemini 3) | До 128 000 токенов (~90 000 слов) | «Большое» (без цифр) | 131 000 токенов (GigaChat 3 Ultra) |
| Открытость | Закрытая (API, ChatGPT Plus) | Закрытая (бесплатно, но с ограничениями) | Закрытая (API) | Закрытая (API через Yandex Cloud) | Закрытая (API через Сбер; бесплатная веб-версия) |
| Доступ в России | нет, потребуются дополнительные средства | нет, потребуются дополнительные средства | нет, потребуются дополнительные средства | Полностью доступна | Полностью доступна (нужен Сбер ID) |
| Поддержка русского языка | Да (но не оптимизирована) | Да (но доступ заблокирован) | Да | Да (оптимизирована, идиомы, локальный контекст) | Да (оптимизирована) |
| Программирование и код | Да | Да | Да | Да | Да |
| Генерация изображений | Нет (только анализ) | Да (редактирование и генерация) | Нет | Нет | Да (через Kandinsky 5.0) |
| Поиск в интернете | Нет | Да (Deep Research) | Нет (но есть Research) | Да (через Поиск Яндекса) | Да (GigaSearch с RAG) |
| Интеграция с экосистемой | API | Google Workspace (Gmail, Диск, Chat) | Google Workspace | Яндекс.Поиск, Карты, Алиса, Станция, Браузер | Сбер ID, СберБанк Онлайн, Домклик, Salute |
| Голосовой ввод/вывод | Нет (только текст) | Да (мобильное приложение) | Нет | Да (через Алису) | Да (GigaAM v3) |
| Бесплатный доступ | Нет (только ChatGPT Plus) | Да (веб и приложение) | Нет | Да (базовый) | Да (веб-версия) |
| Галлюцинации / ограничения | Есть (выдумывает факты) | Есть (особенно в узкоспециализированных областях или при вопросах о малоизвестных событиях и людях) | Разработчики Claude отмечают, что уровень галлюцинаций у их модели ниже, чем у конкурентов. Это связано с применением Конституционального AI в обучении (использование заранее определённых поведенческих принципов) | Есть (ошибки, неточности) | Есть, решается через GigaSearch (RAG) |
Часто задаваемые вопросы (FAQ)
Какую LLM выбрать для бизнеса в России?
Если важна мультимодальность — GigaChat (она работает с изображениями, документами) или GPT-4o. Если нужна открытость и контроль данных — Llama либо Qwen (можно поставить на свои сервера). Для простых задач подойдут YandexGPT или GigaChat — они локализованы и соответствуют российским требованиям.
Как оценить качество и способности модели?
Используйте бенчмарки. Проверьте работу LLM на реальных задачах. Сравните несколько моделей, чтобы выбрать наиболее подходящую.
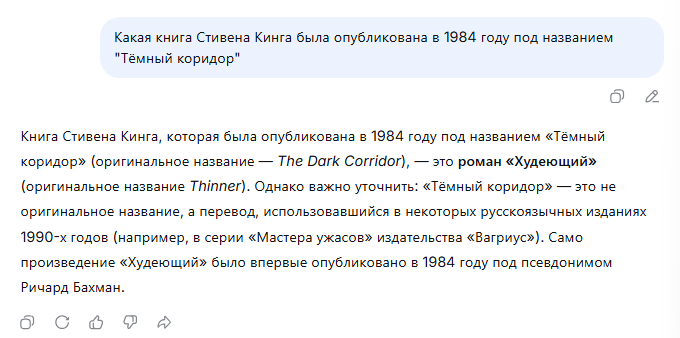
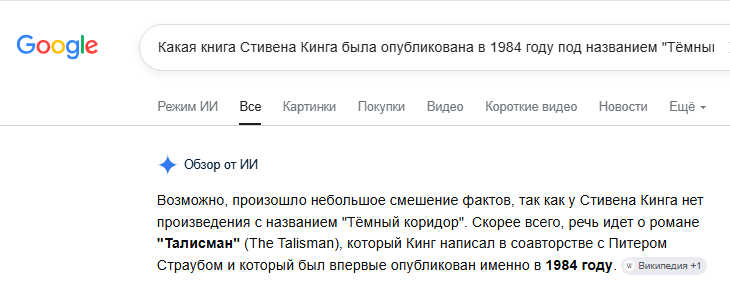
Что такое «галлюцинации» LLM простыми словами?
Это когда нейросеть уверенно выдает полную чушь. Например, вы спрашиваете: «Кто написал роман «Война и мир»?», а она отвечает: «Эрнест Хемингуэй». И пишет это убедительным тоном, с фактами и деталями. Именно поэтому LLM нельзя использовать без проверки в медицине, юриспруденции и других чувствительных сферах.
Как убедиться, что ответ LLM — не галлюцинация?
Всегда проверяйте источники информации. Проводите ручную сверку имен, дат, статистики. LLM может увидеть свою ошибку при повторном запросе, поэтому можно попросить нейросеть проверить предыдущий ответ или сверить его с ответом другой модели.
Полный автопилот с указанием домена и бюджета или тонкая ручная настройка:
Запустить рекламу в PromoPult




