Как закрыть сайт от индексации поисковыми роботами


Чем быстрее страницы сайта индексируются поисковыми роботами, тем быстрее они попадают в поиск. Вот почему SEO-специалисты делают все возможное для попадания сайта в индекс. Однако бывают и обратные ситуации — когда нужно полностью закрыть сайт от индексации или запретить обход определенных страниц. Как и для чего это делается — рассказываем в статье.
Оглавление
- Зачем закрывать сайт или его страницы от индексации
- Что можно закрыть от индексации через robots.txt
- Как запретить индексирование сайта или страниц боту Яндекса
- Как закрыть от индекса страницу, раздел или сайт через файл robots.txt
- Как закрыть от индекса страницу, раздел, сайт и отдельные элементы страницы с помощью HTML-разметки
- Как запретить индексирование с помощью авторизации
- Как проверить статус страницы в Яндекс Вебмастере
- Как закрыть сайт от бота Google
- Как заблокировать доступ робота к странице через robots.txt
- Как запретить индексирование содержимого страницы через HTML-разметку
- Как проверить статус страницы в Google Search Console
- Почему сайт не индексируется
Зачем закрывать сайт или его страницы от индексации
Отображение нового сайта или только что добавленных страниц на поиске происходит не мгновенно. Причина простая — новые страницы еще не проиндексированы поисковыми роботами. Только после того как поисковые роботы проиндексировали добавленные страницы и информация о них поступила в базу данных поисковой системы, страница будет отображаться в поиске Яндекса или Google.
Пользователи видят только те страницы сайта, которые содержат полезный для них контент. Эти страницы открыты для поиска и проиндексированы. Однако каждый ресурс содержит рабочие документы и файлы, которые не несут пользы для посетителей, а нужны разработчикам, администраторам, SEO-специалистам. Сюда относятся временные файлы, рабочая документация, внутренние ссылки, страницы в разработке и другая служебная информация. Попадание таких файлов в индекс только усложнило бы поиск по сайту, сделало бы его структуру непонятной и снизило юзабилити ресурса.
Также от индекса могут закрываться сайты. Это актуально в таких ситуациях: когда разработка сайта еще не окончена, происходит смена контента или дизайна ресурса, меняется структура сайта и т. д.
Четыре причины, почему сайт лучше не индексировать полностью:
- Чтобы не потерять позиции в поисковой выдаче. Не вся информация на сайте полезна для пользователей. Если служебные файлы, страницы в разработке и прочий «мусор» попадет в поиск, бесполезный контент в выдаче приведет к понижению позиций сайта.
- Чтобы выполнить требования к уникальности контента. Поисковые системы требуют, чтобы на ресурсах был уникальный контент. Поэтому если вы, например, тестируете сайт на другом домене, его нужно закрыть от индексации. В противном случае бот воспримет такие страницы как дубли.
Как бороться с дублями, мы рассказывали в этой статье.
- Чтобы у скорить индексацию полезных материалов. Поисковые системы выделяют на каждый ресурс краулинговый бюджет, то есть определенное количество страниц для сканирования. Лучше, чтобы этот лимит был израсходован на полезный для пользователей контент.
- Чтобы не навредить юзабилити. Если меняете структуру или дизайн сайта, лучше на это время скрыть ресурс от поисковых роботов. В противном случае, бот может зафиксировать снижение юзабилити площадки и понизить позиции сайта в выдаче.
Управлять процессом индексирования страниц на сайте помогают два файла:
- sitemap.xml. Карта сайта, которая помогает поисковым роботам ориентироваться среди папок и документов сайта. В этом файле можно прописать частоту обновления контента и приоритет для каждой страницы, тем самым управляя индексом. Карта сайта нужна для больших многостраничных ресурсов и сайтов с глубокой вложенностью. Лендингам и сайтам-одностраничникам карты сайта не нужны.
Как создать XML-карту сайта, читайте в этой статье.
- robots.txt. В этом файле задаются правила для роботов. Именно здесь указываются параметры сканирования сайта или устанавливается запрет для индексации определенных страниц. Инструкция по созданию robots.txt — здесь.
Также для этих целей используется HTML-разметка и консоли вебмастеров — Яндекс Вебмастер и Google Search Console.
Что можно закрыть от индексации через robots.txt
Через robots.txt можно закрыть от индексации весь сайт, папку, файлы и документы, одну или несколько страниц, ссылку или даже отдельный абзац.
Посмотрим, какие страницы, файлы, документы и элементы сайта можно (а в некоторых случаях — необходимо) закрывать от индекса.
Страницы для служебного использования. Сюда относится все, что связано с администрированием — служебные каталоги и разделы сайта. Например, форма авторизации в панели управления, используемая администратором, никак не поможет пользователю выбрать товар на сайте и оформить заказ.
PDF документы. Такие документы могут предназначаться как для служебного использования, так и для пользователей. Например, содержать политику конфиденциальности, условия пользовательского соглашения, данные об ассортименте и ценах компании. Все служебные документы должны быть закрыты от индекса. А в случае с документами для пользователей нужно анализировать поисковую выдачу. В тех ситуациях, когда PDF документы отображаются в рейтинге выше, чем страницы сайта со схожим запросам, их лучше закрыть от индекса, чтобы повысить доступность более важной и релевантной информации.
Формы на сайте и другие элементы. Формы для ввода информации, оформления заказов и регистрации закрываются от индекса, поскольку эта информация бесполезна для поиска. Также закрываются от индекса облака тегов, капча, корзина, всплывающие окна, раздел «Избранное».
Страницы в разработке. Все страницы, на которых меняется дизайн или контент, закрываются от индексации. Также закрываются от индекса дубликаты страниц, поскольку каждая страница должна быть уникальной.
Копии сайта. Бэкап создается для того, чтобы быстро восстановить сайт в том случае, если «слетит» его рабочая версия. В настройках нужно указать корректное зеркало с помощью 301 редиректа. Как настроить 301 редирект, рассказали здесь.
Веб-страницы для печати. Иногда для повышения юзабилити сайта на нем предусматриваются дополнительные функции. Например, функция печати страниц. Такие страницы создаются через дублирование. Если не закрыть от индексации веб-страницы для печати, поисковые системы могут их просканировать и установить копию как приоритетную.
Личные данные пользователей. Данные пользователей должны быть исключены из поисковой выдачи. Поэтому от индекса закрываются личные данные, платежная информация, контактная информация, история покупок и т. д.
Страницы с результатами поиска по сайту. Веб-страницы с результатами поиска важны для пользователей, которые ищут на сайте информацию, однако она не важна для поиска. Поэтому такие страницы также закрываются от поисковых роботов, как и страницы с личными данными.
Как запретить индексирование сайта или страниц боту Яндекса
Запретить поисковому роботу Яндекса индексировать сайт можно тремя способами: через файл robots.txt, HTML-разметку или авторизацию на сайте.
Как закрыть от индекса страницу, раздел или сайт через файл robots.txt
Основным поисковым ботом Яндекса является YandexBot. Именно для него прописываются директивы, чтобы закрыть ресурс или отдельные страницы от индексации. Кроме Яндексбота у Яндекса есть более десятка других роботов, каждый из которых выполняет свою задачу. Например, YandexMetrika — это робот Яндекс Метрики, YandexMarket — робот Маркета, YandexMedia — робот, который индексирует мультимедийные данные.
Для закрытия страницы от индексирования прописывается директива именно для YandexBot. Рассказываем, как это сделать и какие команды прописывать.
Перейдите в robots.txt и пропишите там директиву Disallow. Директива Disallow запрещает поисковому боту Яндекса обход отдельных страниц или целых разделов сайта. С ее помощью можно закрыть от индекса дубли страниц, разнообразные логи, сервисные страницы, страницы с конфиденциальными данными и т. д.
Какие команды можно прописать в файле robots.txt
Для запрета роботу Яндекса обходить весь сайт пропишите:
User-agent: Yandex
Disallow: /
Для запрета обхода только тех страниц, адрес которых начинается с /catalogue, пропишите такую команду:
User-agent: Yandex
Disallow: / catalogue
Для запрета обхода страниц, URL которых содержит параметры, пропишите:
User-agent: Yandex
Disallow: /page? — директива запрещает обход страниц, URL которых содержит параметры.
Как закрыть от индекса страницу, раздел, сайт и отдельные элементы страницы с помощью HTML-разметки
Как закрыть страницу от индекса
Если хотите закрыть от индекса определенные страницы сайта, пропишите в элементе head в HTML-коде метатег robots с директивой noindex, nofollow или none.
Что обозначают эти директивы:
- noindex. Директива запрещает поисковому роботу индексировать текст страницы. Закрытая этой директивой страница не будет участвовать в результатах поиска.
- nofollow. Директива запрещает боту переходить по ссылкам на странице.
- none. Эта директива не только запрещает роботу индексировать страницу, но и запрещает ему переходить по ссылкам на ней.
Например, если вам надо скрыть определенный контент на странице и предупредить его появление в поиске, пропишите следующее:
<meta name="yandexbot" content="noindex, nofollow">.
Если вам нужно закрыть целый раздел сайта, пропишите директиву noindex в HTML-коде на каждой странице раздела.
Подробнее об использовании директив noindex и nofollow — в этой статье.
Как закрыть от индексирования часть текста
Если вы хотите скрыть от бота определенную часть текста на странице, добавьте элемент noindex в HTML-код страницы.
Это будет выглядеть так:
<noindex>текст, который нужно скрыть от индексирования</noindex>
Еще один вариант — использовать директиву noscript:
<noscript>текст, который нужно скрыть от индексирования</noscript>
Эта директива позволяет не только запретить роботу индексировать часть этой страницы, но и скрыть этот отрывок от пользователей (при условии, что браузер пользователя использует технологию JavaScript).
Как закрыть ссылку от индексирования
Если вам нужно не закрывать страницу от индексирования, но запретить роботу переходить по ссылкам, используйте директиву nofollow. Директива прописывается в HTML-разметке по тексту и проставляется там, где находится ссылка.
Как запретить индексирование с помощью авторизации
Если нужно скрыть от индексации главную страницу сайта, использование авторизации будет эффективнее, чем закрытие страницы от индекса в файле robots.txt. Причина — даже если главная страница закрыта для поиска в robots.txt, но на нее ведут ссылки с других сайтов, такая страница все равно может попасть в индекс.
Иногда неавторизованные пользователи могут попадать на закрытые страницы. Чтобы предупредить эту ситуацию, для таких страниц нужно настроить код ответа сервера 404 Not Found. Подробнее об ошибке 404 читайте здесь.
Как проверить статус страницы в Яндекс Вебмастере
Даже после того, как вы провели все необходимые действия по закрытию в robots.txt сайта или его отдельных страниц от индексирования, поисковые системы могут игнорировать прописанные директивы. В результате сайт может попасть в индекс полностью.
Поэтому важно проверять статус сайта и его страниц. Провести такую проверку можно в Яндекс Вебмастере.
Для проверки статуса отдельной страницы перейдите в раздел «Индексирование» → «Проверка страницы».
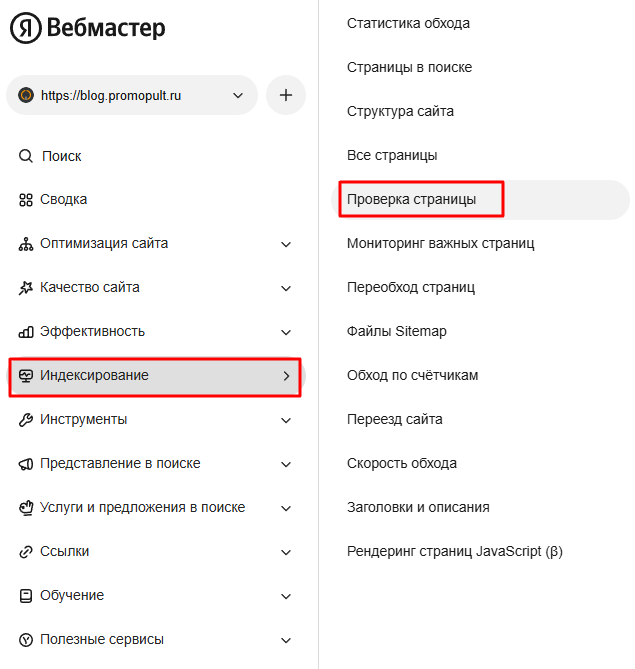
Укажите адрес страницы и нажмите на кнопку «Проверить».
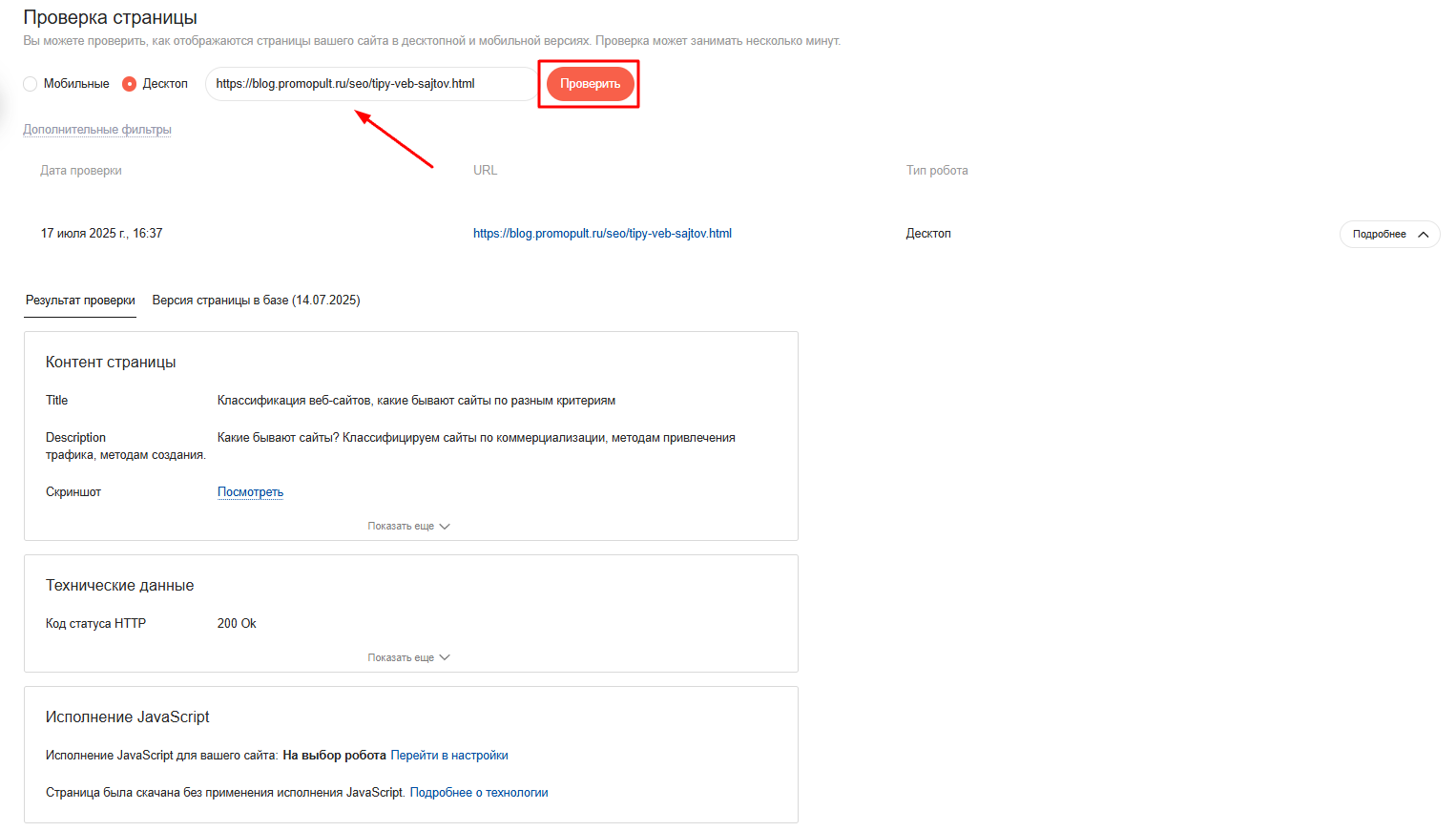
В сформированном отчете будут содержаться такая информация:
- код статуса HTTP;
- время ответа сервера;
- кодировка;
- дата и время последнего сканирования страницы поисковым роботом;
- состояние в поиске;
- статус страницы во время последнего обхода роботом;
- содержимое title и description;
- исполнение кода JavaScript.
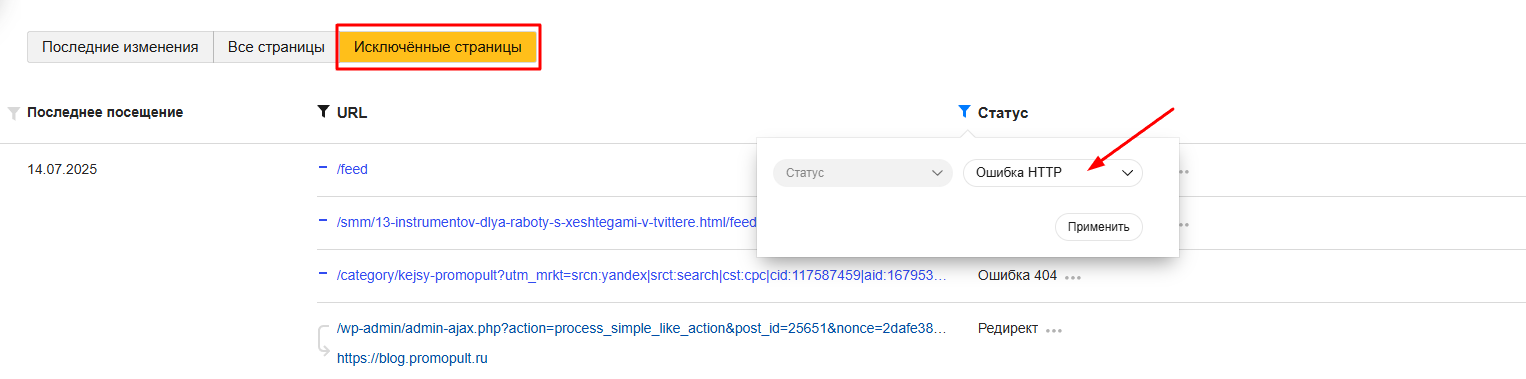
Для проверки всех проиндексированных страниц сразу перейдите в раздел «Индексирование» → «Страницы в поиске». Сформированный отчет будет состоять из таблицы со списком URL страниц, их статусами, заголовками и датами последней индексации.
Для того чтобы в этом отчете найти страницы, удаленные из результатов поиска, нужно в столбце «Статус» отсортировать результаты по статусу «Ошибка HTTP». В этом случае в отчете появится список адресов страниц, которые удалены из результатов поиска, и указан код ошибки.
Полное руководство по Яндекс Вебмастеру читайте здесь.
Как закрыть сайт от бота Google
Заблокировать поисковым роботам Google доступ к сайту можно также через robots.txt, HTML-разметку или указать инструкцию для Googlebot в HTTP-заголовке.
Как заблокировать доступ робота к странице через robots.txt
Основным поисковым роботом Google является Googlebot. Его задача — индексировать страницы и проверять их на адаптивность под мобильные устройства. Но также у Google есть десяток других ботов, каждый из которых выполняют свою задачу. Например, Googlebot-News сканирует страницу с новостями и добавляет их в Google Новости, Googlebot-Video индексирует видеоконтент на страницах сайта, а Googlebot-Image — изображения.
Управление индексированием сайта или отдельных его страниц для Googlebot в файле robots.txt происходит с помощью той же директивы Disallow, что и для поискового робота Яндекса.
То есть, для того чтобы закрыть обход всего сайта для бота Google, в файле укажите:
User-agent: Googlebot
Disallow: /
Если вам надо закрыть обход определенной страницы, пропишите такую директиву:
User-agent: Googlebot
Disallow: / page
Для закрытия обхода раздела прописывается директива:
User-agent: Googlebot
Disallow: / catalogue
Для закрытия раздела с новостями от индекса поисковым роботом Googlebot-News пропишите директиву:
User-agent: Googlebot-News
Disallow: / news
Если нужно закрыть сайт полностью от поисковых роботов Яндекса и Google, не обязательно прописывать для них разные директивы. Это можно сделать одной командой.
User-agent: *
Disallow: /
В первой строке вместо имени агента ставится знак «*».
Как запретить индексирование содержимого страницы через HTML-разметку
С помощью HTML-разметки можно закрыть от индексации роботом Google целую страницу или определенную ее часть. Для этого пропишите метатег «googlebot» с директивой noindex или none.
Для того чтобы ограничить боту Google доступ к странице вашего сайта, на HTML-странице вы можете прописать такие команды:
1. Если хотите скрыть определенный контент на странице и предупредить его появление на поиске и в Google News, пропишите команду:
<meta name="googlebot" content="noindex, nofollow">
2. Если хотите запретить индексирование определенных изображений на странице, пропишите команду:
<meta name="googlebot" content="noimageindex">
3. Если на сайте очень быстро устаревает актуальность контента, например, у вас новостной портал, или вы проводите акции и не хотите, чтобы в индекс попадали страницы с неактуальной информацией, пропишите команду, когда страница должна быть удалена из индекса Google.
Например, вы разместили на сайте новость о проведении Черной пятницы. Срок окончания акции — 29 ноября. Команда будет выглядеть так:
<meta name="googlebot" content="unavailable_after: 29-Nov-2023 15:00:00 EST">
Что касается индексирования ссылок, в Google есть два дополнительных параметра, которые указывают поисковику на происхождение линков:
- rel="ugc" — используется в том случае, если у вас на ресурсе есть форум, где пользователи делятся отзывами и оставляют свои ссылки. В качестве таких ссылок сложно быть уверенным, и этот атрибут помогает роботу понять, откуда взялась ссылка.
- rel="sponsored" — используется в том случае, если на сайте размещена рекламная ссылка, которая указывает на размещение в рамках партнерской программы.
Как проверить статус страницы в Google Search Console
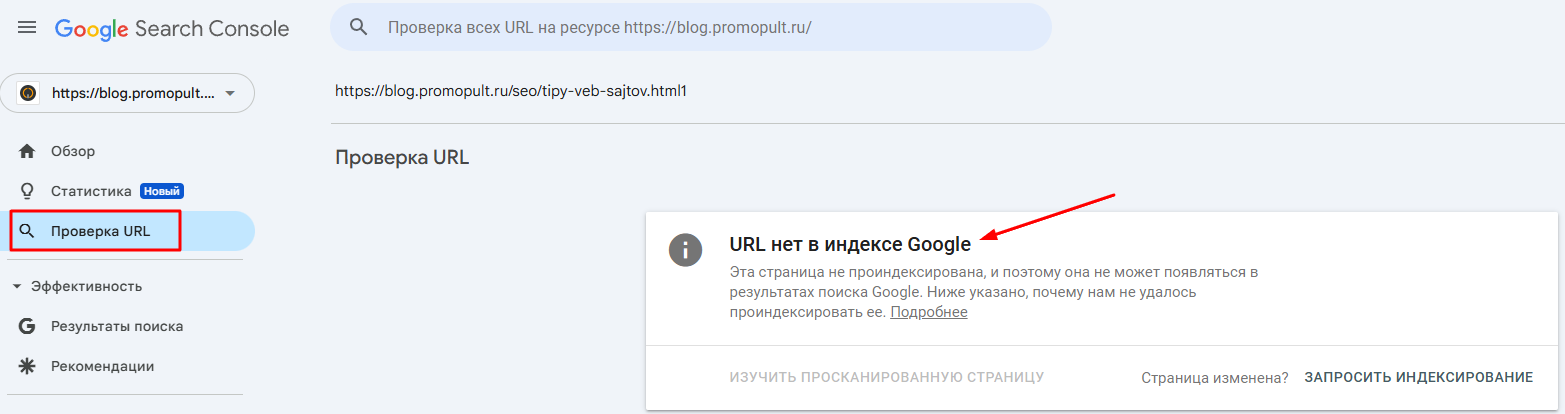
В Google Search Console также предусмотрена возможность проверки статуса страницы. Для этого в боковой панели выберите раздел «Инструмент проверки URL», введите нужный адрес и кликните на «Изучить просканированную страницу».
Если страница исключена из индексирования, в отчете будет сообщение о том, что URL нет в индексе Google.
В Google Search Console также можно проверить все страницы сайта. Для этого перейдите в раздел «Индексирование» → «Страницы» и сформируйте отчет с результатами сканирования. В отчете будут представлены результаты сканирования, сгруппированные по статусу (ошибка, предупреждение, без ошибок) и причине.
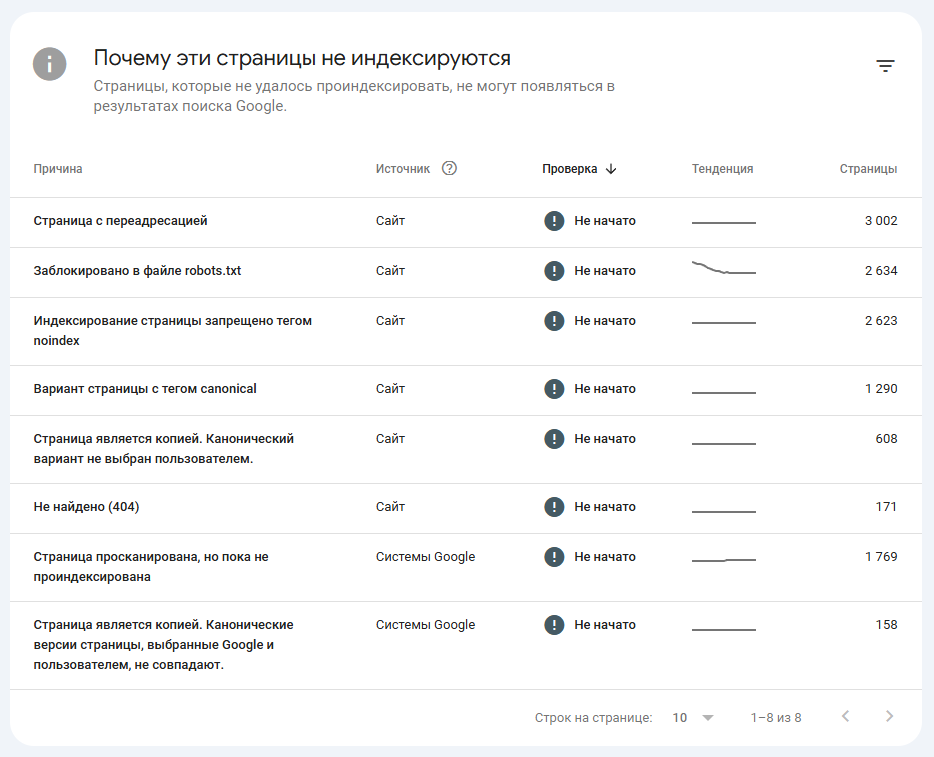
Читайте руководство по Google Search Console в блоге PromoPult.
Кроме Google Search Console и Яндекс Вебмастера существуют и другие инструменты и онлайн-сервисы, позволяющие проверить статус страниц сайта. Например, в PromoPult есть «Анализ индексации страниц», который быстро проверит индексацию всего сайта или отдельных страниц в Яндексе и Google. Нужно только загрузить XML-карту, XLSX-файл со списком URL или ввести нужные адреса страниц вручную. Подробная инструкция по работе с инструментом — здесь.
Реклама. ООО «Клик.ру», ИНН:7743771327, ERID: 2Vtzqwf7ySw
Почему сайт не индексируется
Иногда происходит так, что сайт не индексируется поисковыми системами, хотя никаких специальных мер для этого не предпринималось.
Почему так может случиться:
- Сайт новый. Поисковикам требуется время на индексирование нового сайта. Но этот процесс можно ускорить. Например, запросить индексирование страниц можно в Яндекс Вебмастере или Google Search Console.
- Настройки приватности на сайтах с готовой CMS. На таких площадках часто стоят настройки приватности по умолчанию, из-за чего сайт не индексируется поисковыми системами.
- Сайт заблокирован в файле robots.txt. Просмотрите содержимое файла и убедитесь, что в нем не прописаны директивы, которые закрывают сайт от индекса.
- Проблемы с хостингом или сервисом. Если во время обхода бота сайт был недоступен, страницы не будут внесены в базы данных поисковых систем.
- Ошибки при сканировании. При большом количестве ошибок бот не может обойти сайт. Проверить сайт на наличие ошибок можно в панелях вебмастеров.
- Доступ к сайту закрыт в файле htaccess. Проверьте файл на содержание запрещающих индексирование команд.
- Отсутствует карта сайта. Файл sitemap.xml необходим для многостраничных сайтов и иногда может стать причиной «незаметности» ресурса для поисковых систем.
Хотите избежать ошибок в индексации сайта — подключайте модуль SEO в PromoPult. Специалисты выполнят задачи по чек-листу и в срок, инструменты на основе искусственного интеллекта подберут ключевые запросы, распределят их по страницам, выявят ошибки в технической оптимизации. Часть задач можно сделать самостоятельно или делегировать своим сотрудникам, тем самым сэкономив бюджет. И главное: SEO в PromoPult можно протестировать 2 недели бесплатно. Мы выполним задачи по базовой оптимизации, проставим ссылки на авторитетных ресурсах, разместим контент под информационные запросы. Вы примете решение, продолжать ли продвигаться, на основе результатов.
Реклама. ООО «Клик.ру», ИНН:7743771327, ERID: 2Vtzqwf7ySw
Полный автопилот с указанием домена и бюджета или тонкая ручная настройка:
Запустить рекламу в PromoPult





