Как составить правильный robots.txt для Яндекса и Google [инструкция]

![Как составить правильный robots.txt для Яндекса и Google [инструкция]](https://blog.promopult.ru/wp-content/webp-express/webp-images/uploads/2021/10/34787685564.png.webp)
Вебмастер может направить поисковых ботов на разделы, которые считает обязательными для индексирования, и скрыть те, которых в выдаче быть не должно. Для этого предназначен файл robots.txt. Мы составили гайд об этом файле: для чего он нужен, из каких команд состоит, как составить его по правилам и проверить.
Оглавление
Зачем нужен robots.txt
С помощью этого файла можно повлиять на поведение ботов Яндекса и Google. Robots.txt содержит указания для краулеров, предназначенных для индексирования сайта. Он состоит из списка директив, которые рекомендуют либо просканировать, либо пропустить конкретные страницы или целые разделы сайта. Если боты «прислушаются» к этим пожеланиям, то не будут посещать закрытые рубрики или индексировать определенный тип контента.
Закрывают обычно дублирующие страницы, служебные, неинформативные, страницы с GET-параметрами или просто неважные для пользователей.
Зачем это нужно:
- уменьшить количество запросов к серверу;
- оптимизировать краулинговый бюджет сайта — общее количество URL, которое за один раз может посетить поисковый бот;
- уменьшить шанс того, что в выдачу попадут страницы, которые там не нужны.
Как надежно закрыть страницу от ботов
Поисковики не воспринимают robots.txt как список жестких правил, это только рекомендации. Даже если в robots стоит запрет, страница может появиться в выдаче, если на нее ведет внешняя или внутренняя ссылка.
URL-адрес, доступ к которому запретили только в robots.txt, может попасть в выдачу и будет выглядеть так:

Если вы точно не хотите, чтобы URL попал в индекс, недостаточно запретить сканирование в robots.txt. Один из вариантов, подходящий для служебных страниц, — запаролить ее. Бот не сможет просканировать содержимое страницы, если она доступна только пользователям, авторизованным через логин и пароль.
Если страницы нельзя закрыть паролем, но не хочется показывать их ботам, есть вариант применить директивы «noindex» и «nofollow». Для этого нужно добавить их в секцию
HTML-кода:<meta name="robots" content="noindex, nofollow"/>
Чтобы робот правильно интерпретировал «noindex» и «nofollow» и не добавил страницу в индекс, не закрывайте одновременно доступ к ней в robots.txt. Так бот не сможет пройти по URL и не увидит запрещающих директив.
Требования поисковых систем к robots.txt
Каким должен быть файл, как его оформить и куда размещать — в этом и Яндекс, и Google солидарны:
- Формат — только txt.
- Вес — не превышающий 32 КБ.
- Название — строго строчными буквами «robots.txt». Никакие другие варианты, к примеру, с заглавной, боты не воспримут.
- Наполнение — строго латиница. Все записи должны быть на латинице, включая адрес сайта: если он кириллический, его нужно переконвертировать в punycode. Например, после конвертации запись сайта «окна.рф» будет выглядеть как «xn--80atjc.xn--p1ai». Ее и нужно использовать в командах.
- Исключение для предыдущего правила — комментарии вебмастера. Они могут быть на любом языке, поскольку специалист оставляет их для себя и коллег, а не для поисковых ботов. Для обозначения комментариев используют символ «#». Все, что указано после «#», роботы проигнорируют, поэтому следите, чтобы туда случайно не попали важные директивы.
- Количество файлов robots.txt — должен быть один общий файл на весь сайт вместе с поддоменами.
- Местоположение — корневой каталог. У поддоменов файл должен быть таким же, только разместить его нужно в корневом каталоге каждого поддомена.
- Ссылка на файл — https://example.com/robots.txt (вместо https://example.com нужно указать адрес вашего сайта).
- Ссылка на robots.txt должна отдавать код ответа сервера 200 OK.
- Найти ошибки в заполнении robots — инструмент от Яндекса. Укажите сайт и введите содержимое файла в поле.
- Проверить доступность для поисковых роботов — инструмент от Google. Введите ссылку на URL с вашим robots.txt.
- Определить наличие robots.txt в корневом каталоге и доступность сайта для индексации — Анализ сайта от PR-CY. В сервисе есть еще 70+ тестов с проверкой SEO, технических параметров, ссылок и другого.
Подробные рекомендации для robots.txt от Яндекса читайте здесь, от Google — здесь.
Дальше рассмотрим, каким образом можно давать рекомендации ботам.
Как правильно составить robots.txt
Файл состоит из списка команд (директив) с указанием страниц, на которые они распространяются, и адресатов — имён ботов, к которым команды относятся.
Директиву Clean-param воспринимают только поисковые роботы Яндекса, а в остальном в 2021 году команды для ботов Google и Яндекса одинаковы.
Основные обозначения
User-agent — какой бот должен прореагировать на команду. После двоеточия указывают либо конкретного бота, либо обобщают всех с помощью символа *.
Пример. User-agent: * — все существующие роботы, User-agent: Googlebot — только бот Google.
Disallow — запрет сканирования. После косого слэша указывают, на что распространяется команда запрета.
Пример:

Пустое поле в Disallow означает разрешение на сканирование всего сайта:

А эта запись запрещает всем роботом сканировать весь сайт:

Если речь идет о новом сайте, проследите, чтобы в robots.txt не осталась эта директива, после того как разработчики выложат сайт на рабочий домен.
Эта запись разрешает сканирование поисковому боту Google, а всем остальным запрещает:

Отдельно прописывать разрешения необязательно. Доступным считается всё, что вы не закрыли.
В записях важен закрывающий косой слэш, его наличие или отсутствие меняет смысл:
Disallow: /about/ — запись закрывает раздел «О нас», доступный по ссылке https://example.com/about/
Disallow: /about — закрывает все ссылки, которые начинаются с «/about», включая раздел https://example.com/about/, страницу https://example.com/about/company/ и другие.
Каждому запрету соответствует своя строка, нельзя перечислить несколько правил сразу. Вот неправильный вариант записи:

Правильно оформить их раздельно, каждый с новой строки:

Allow означает разрешение сканирования, с помощью этой директивы удобно прописывать исключения. Для примера запись запрещает всем ботам сканировать весь альбом, но делает исключение для одного фото:

А вот и отдельная команда для Яндекса — Clean-param. Директиву используют, чтобы исключить дубли, которые могут появляться из-за GET-параметров или UTM-меток. Clean-param распознают только боты Яндекса. Вместо нее можно использовать Disallow, эту команду понимают в том числе и гуглоботы.
Допустим, на сайте есть страница page=1 и у нее могут быть такие параметры:
https://example.com/index.php?page=1&sid=2564126ebdec301c607e5df
https://example.com/index.php?page=1&sid=974017dcd170d6c4a5d76ae
Каждый образовавшийся адрес в индексе не нужен, достаточно, чтобы там была общая основная страница. В этом случае в robots нужно задать Clean-param и указать, что ссылки с дополнениями после «sid» в страницах на «/index.php» индексировать не нужно:

Если параметров несколько, перечислите их через амперсанд:
Clean-param: sid&utm&ref /index.php
Строки не должны быть длиннее 500 символов. Такие длинные строки — редкость, но из-за перечисления параметров такое может случиться. Если указание получилось сложным и длинным, его можно разделить на несколько. Примеры найдете в Справке Яндекса.
Sitemap — ссылка на карту сайта. Если карты сайта нет, запись не нужна. Сама по себе карта не обязательна, но если сайт большой, то лучше ее создать и дать ссылку в robots, чтобы поисковым ботам было проще разобраться в структуре.
Sitemap: https://example.com/sitemap.xml
Обозначим также два важных спецсимвола, которые используются в robots:
* — предполагает любую последовательность символов после этого знака;
$ — указывает на то, что на этом элементе необходимо остановиться.
Пример. Такая запись:

запрещает роботу индексировать site.com/catalog/category1, но не запрещает индексировать site.com/catalog/category1/product1.
Лучше не заниматься сбором команд вручную, для этого есть сервисы, которые работают онлайн и бесплатно. Инструмент для генерации robots.txt бесплатно соберет нужные команды: открыть или закрыть сайт для ботов, указать путь к sitemap, настроить ограничение на посещение избранных разделов, установить задержку посещений.
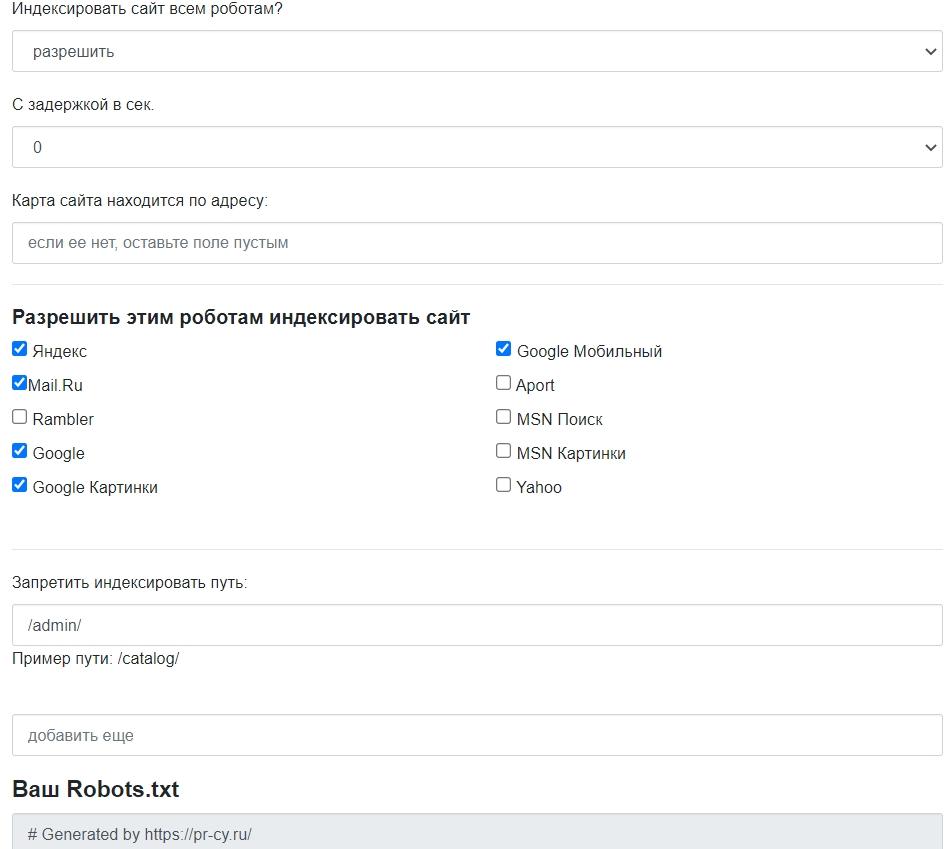
Есть и другие бесплатные генераторы файла, которые позволят быстро создать robots и избежать ошибок. У популярных движков есть плагины, с ними собирать файл еще проще. О них расскажем ниже.
Как проверить правильность robots.txt
После создания файла и добавления в корневой каталог будет не лишним проверить, видят ли его боты и нет ли ошибок в записи. У поисковых систем есть свои инструменты:
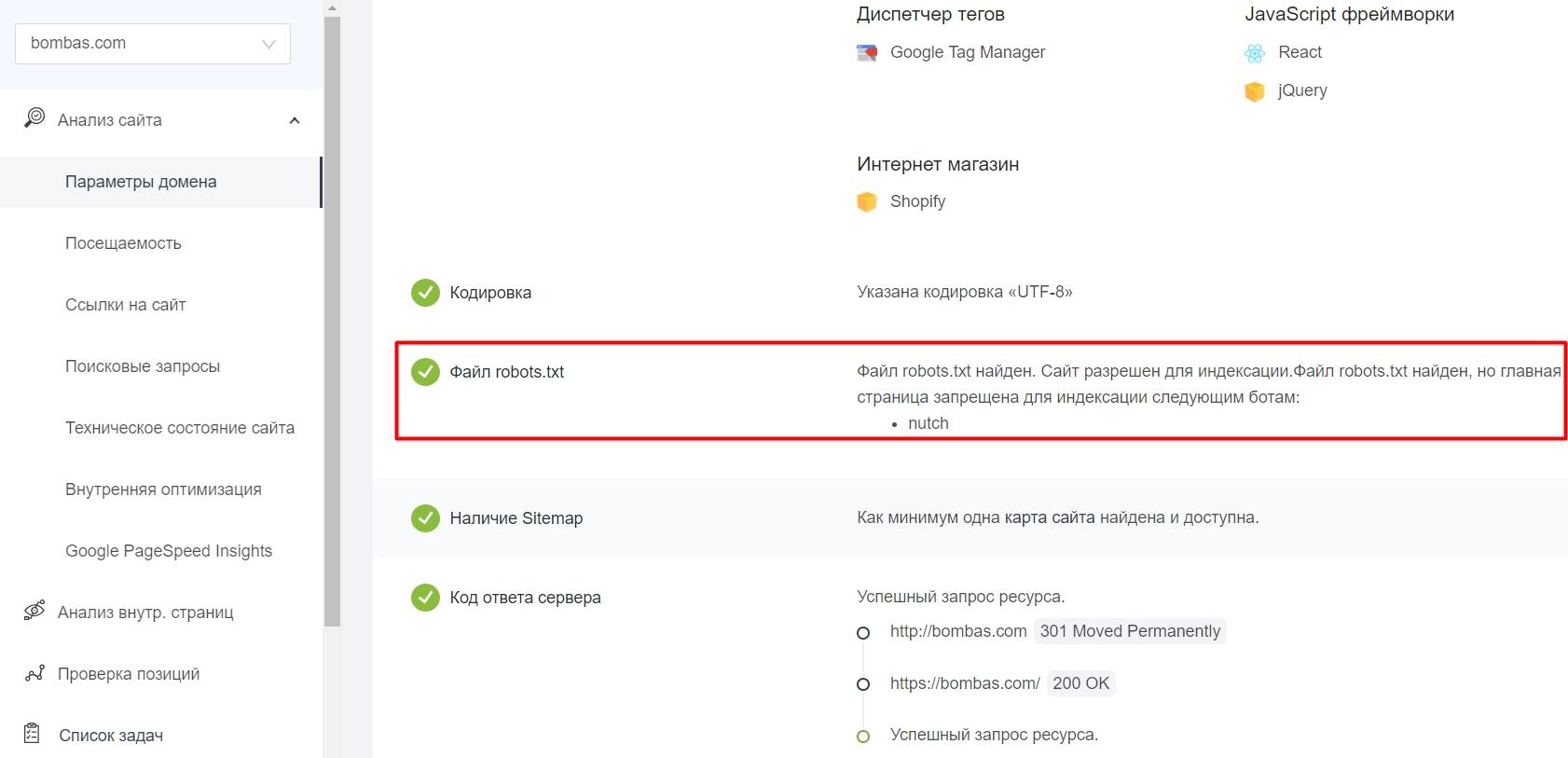
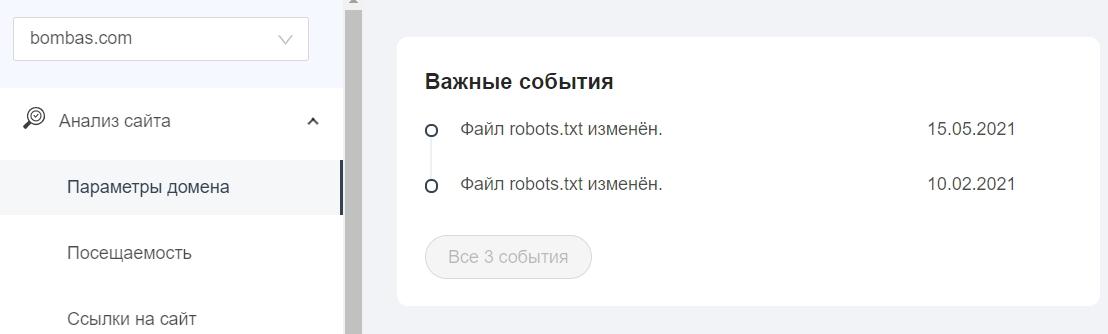
В «Важных событиях» отобразятся даты изменения файла.
Правильный robots.txt для разных CMS: примеры готового файла
Файл robots.txt находится в корневой папке сайта. Чтобы создать или редактировать его, нужно подключиться к сайту по FTP-доступу. Некоторые системы управления (например, Битрикс) предоставляют возможность редактировать файл в административной панели.
Посмотрим, какие возможности для редактирования robots.txt есть в популярных CMS.
WordPress
У WP много бесплатных плагинов, которые формируют robots.txt. Эта опция предусмотрена в составе общих SEO-плагинов Yoast SEO и All in One SEO, но есть и отдельные, которые отвечают за создание и редактирование файла, например:
Пример robots.txt для контентного проекта на WordPress
Это вариант файла для блогов и других проектов без функции личного кабинета и корзины.

Пример robots.txt для интернет-магазина на WordPress
Похожий файл, но со спецификой интернет-магазина на платформе WooCommerce на базе WordPress. Закрываем то же самое, что в предыдущем примере, плюс саму корзину, а также отдельные страницы добавления в корзину и оформления заказа пользователем.

1C-Битрикс
В модуле «Поисковая оптимизация» этой CMS начиная с версии 14.0.0 можно настроить управление robots из административной панели сайта. Нужный раздел находится в меню Маркетинг > Поисковая оптимизация > Настройка robots.txt.
Пример robots.txt для сайта на Битрикс
Похожий набор директив с дополнениями, подразумевающими, что у сайта есть личный кабинет пользователя.

OpenCart
У этого движка есть официальный модуль Редактирование robots.txt Opencart для работы с файлом прямо из панели администратора.
Пример robots.txt для магазина на OpenCart
CMS OpenCart обычно используют в качестве базы для интернет-магазина, поэтому пример robots заточен под нужды e-commerce.
User-agent: *
Disallow: /*route=account/
Disallow: /*route=affiliate/
Disallow: /*route=checkout/
Disallow: /*route=product/search
Disallow: /index.php?route=product/product*&manufacturer_id=
Disallow: /admin
Disallow: /catalog
Disallow: /system
Disallow: /*?sort=
Disallow: /*&sort=
Disallow: /*?order=
Disallow: /*&order=
Disallow: /*?limit=
Disallow: /*&limit=
Disallow: /*?filter=
Disallow: /*&filter=
Disallow: /*?filter_name=
Disallow: /*&filter_name=
Disallow: /*?filter_sub_category=
Disallow: /*&filter_sub_category=
Disallow: /*?filter_description=
Disallow: /*&filter_description=
Disallow: /*?tracking=
Disallow: /*&tracking=
Disallow: *page=*
Disallow: *search=*
Disallow: /cart/
Disallow: /forgot-password/
Disallow: /login/
Disallow: /compare-products/
Disallow: /add-return/
Disallow: /vouchers/
Sitemap: https://example.com/sitemap.xml
Joomla
Отдельных расширений, связанных с формированием robots.txt для этой CMS нет, система управления автоматически генерирует файл при установке, в нем содержатся все необходимые запреты.
Пример robots.txt для сайта на Joomla
В файле закрыты плагины, шаблоны и прочие системные решения.
User-agent: *
Disallow: /administrator/
Disallow: /cache/
Disallow: /components/
Disallow: /component/
Disallow: /includes/
Disallow: /installation/
Disallow: /language/
Disallow: /libraries/
Disallow: /media/
Disallow: /modules/
Disallow: /plugins/
Disallow: /templates/
Disallow: /tmp/
Disallow: /*?start=*
Disallow: /xmlrpc/
Allow: *.css
Allow: *.js
Sitemap: https://example.com/sitemap.xml
Поисковые роботы воспринимают директивы в robots.txt как рекомендации, которым можно следовать или не следовать. Тем не менее, если в файле не будет противоречий, а на закрытые разделы нет входящих ссылок — у ботов не будет причин игнорировать правила. Пользуйтесь нашими инструкциями и примерами, и пусть в выдаче появляются только действительно нужные пользователям страницы вашего сайта.
В SEO-модуле PromoPult перед продвижением проверят техническое состояние сайта, в том числе и файла robots.txt, и составят чек-лист с задачами по внутренней оптимизации. Их могут выполнить специалисты платформы, сам владелец ресурса или его сотрудники. В PromoPult простой интерфейс, большинство сложных технических процессов выполняют AI инструменты, от подбора семантики до технического аудита, что экономит время и бюджет. Протестировать SEO в PromoPult можно бесплатно за 2 недели, а успешные кейсы в вашей нише найдёте тут.
Реклама. ООО «Клик.ру», ИНН:7743771327, ERID: 2VtzqwXqNpZ
Полный автопилот с указанием домена и бюджета или тонкая ручная настройка:
Запустить рекламу в PromoPult




